
2026年03月05日 07:30

AI搭載型データ活用BIプラットフォーム Domo(ドーモ)では、複雑な条件で自社データを抽出する方法として、UI画面上だけでSQLクエリを直感的に作成するMagic ETLと、従来型のSQLを記載するSQL DataFlowの2種類があります。この記事ではこれらの特徴と、使い分けをするためのベストプラクティスなどをご紹介いたします。
この記事を読めば、DomoでSQLクエリを使用して効率的にデータ抽出を行う手段が分かるだけでなく、Domoの負荷を軽減させるポイントについても理解できるようになりますので、ぜひ最後までお読みください。
Domo(ドーモ)でデータ抽出する2つの方法
Domo上で条件を指定してデータを抽出する方法として、主に以下2つのいずれかの機能を利用することが一般的です。
それぞれの特徴を理解し利用することが大切ですが、パフォーマンスの観点で言えばMagic ETLを利用する方が良いでしょう。この章では、それらの理由について詳しく解説していきます。
-
Magic ETL DataFlow
Magic ETL DataFlow(以下、Magic ETL)とは、画面上でドラッグアンドドロップによって処理を作成し、簡単に複数のソースからデータを取得・処理・変換してDomoに読み込める機能です。SQLのコーディングは不要な一方、画面上のアイコン(タイル)の順序を追うだけで、どんな処理がされるのかを簡単に理解できます。
Magic ETLでできる11の機能
Magic ETL上のタイルは全部で11種類のテーマがあり、それぞれのテーマでさらに利用可能なタイルが複数個含まれております。各タイルにはそれぞれ処理コードが記載されており、細かい条件設定をGUI上から行います。以下は、その概要です。
Magic ETLの主な機能 機能詳細 集計 グループ化:複数の列の値を1つの列にまとめて集計 ランクとウィンドウ:順序の指定、テーブルから集合部分を切り出して処理をかける データ結合 行を追加:複数のDataSetのデータを利用して指定したDataSetへ一行追加する データを結合:2つのDataSetまたはデータ「ストリーム」の列を1つのDataSetに結合する データサイエンス AIモデル推論:Domo内のDataSetへ任意のAIモデルを選択・適用させ、結論や出力を導く AutoML推論:Amazon SageMaker Autopilotと連携し、入力するDataSetから予測を生成する 分類:データ内の列の値を、統計モデルを用いて値ごとにグループを作成し分類する クラスタリング:データ間の類似性を発見しグループ化する 予測:ARIMAアルゴリズムまたは回帰アルゴリズを用い、既存データから未来観測値を予測する 多変量外れ値:外れ値または異常観測値を検出する 外れ値検出:DataSet内の数値列の外れ値または異常観測値を検出する DataSet DataSetを入力、出力、ライトバック(別システムへのデータ送信)する 日付と数値 計算機:計算した値を列に追加する 日付の演算:日付値の演算結果を列に追加する フィルター 行をフィルター:ルールを指定し条件別にフィルターをかける 重複を削除:特定の列の値が重複する行を削除 パフォーマンス PythonまたはRスクリプト処理を速める処理を実行する ピボット データの列を正規化または非正規化する スクリプティング カスタムのRまたはPythonアルゴリズムを記述して、DataFlowに直接実装する テキスト 複数列の文字列結合、テキスト置換、文字列分割、文字列演算、書式設定などを行う ユーティリティ 定数やスクリプトの追加、列の抽出や並べ替え、列の値変換をする ただし以下の処理は、他のタイルと比較し時間がかかる傾向がありますので、利用時には注意してください。
- グループ化
- ランクとウィンドウ
- データを結合
- 重複を削除
- ピボット
- スクリプティング
- データサイエンス
Magic ETLのGUI
Magic ETLを利用するには、まず「データ」を開き、「データを変換」から「Magic ETL」を選択して開きます。
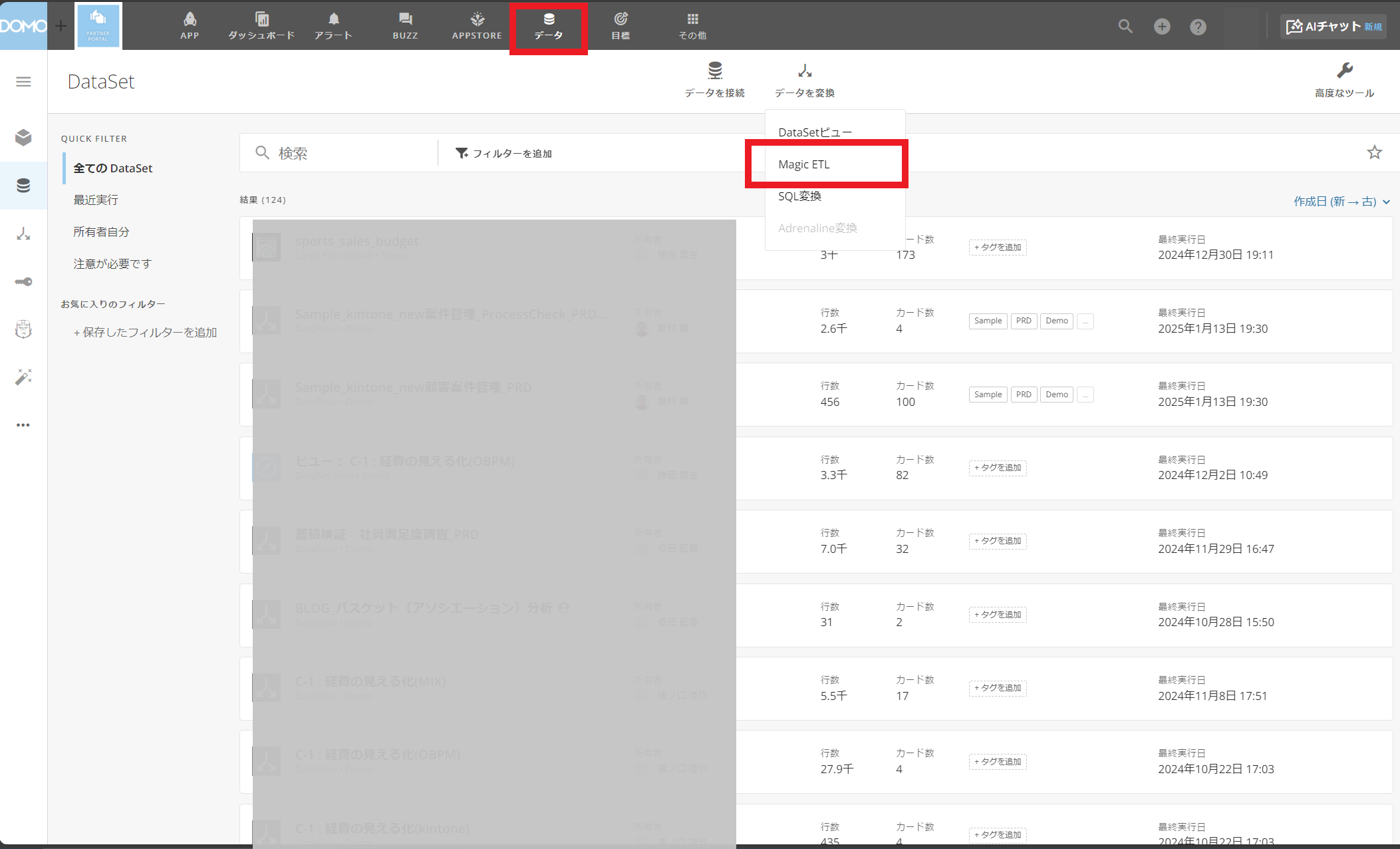
Magic ETLを起動すると、以下の画面が開きます。基本は、「入力Dataset」>「拡張(処理)」>「出力Dataset」の流れを意識し、左のタイルからドラッグアンドドロップして一連の処理を作成していきます。
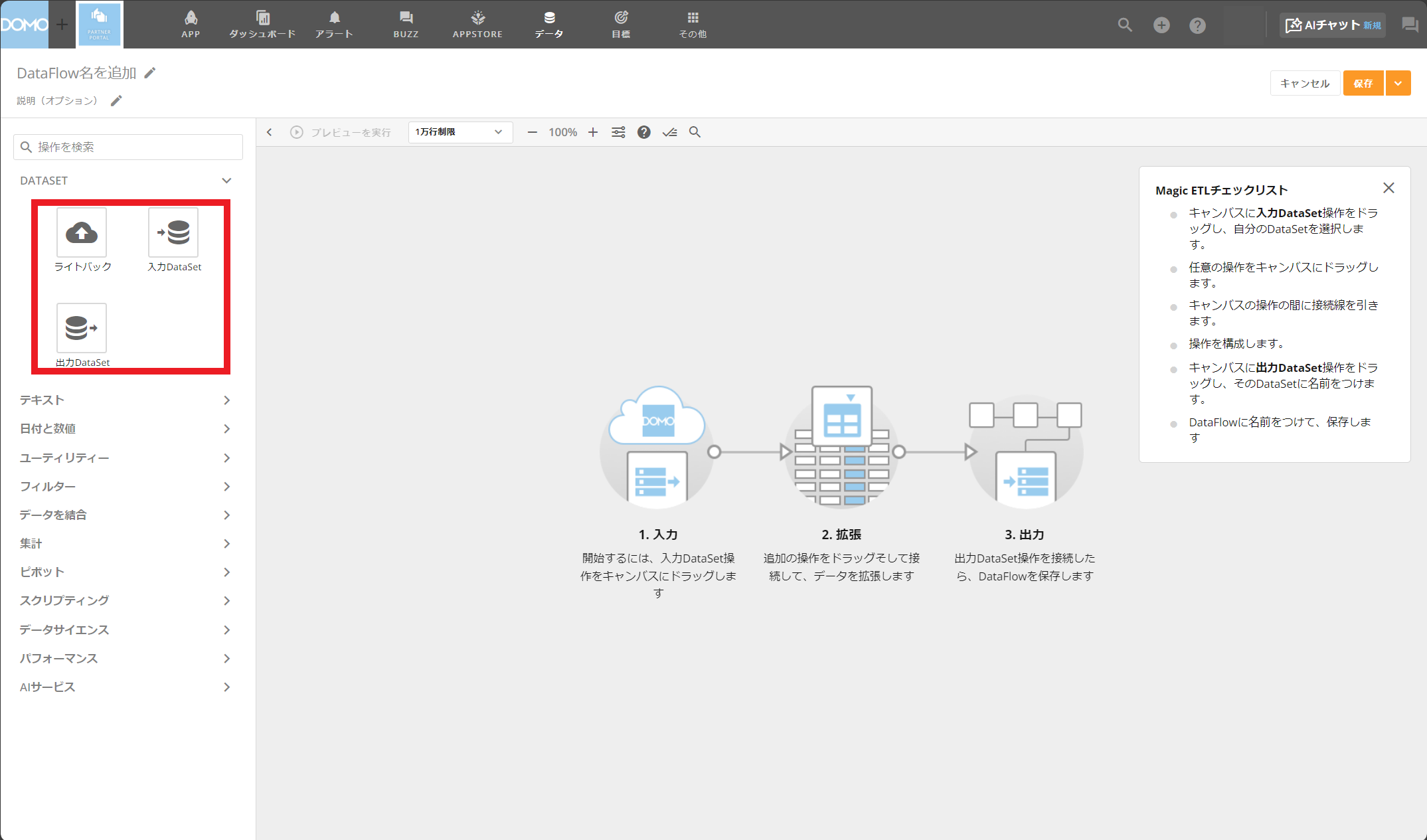
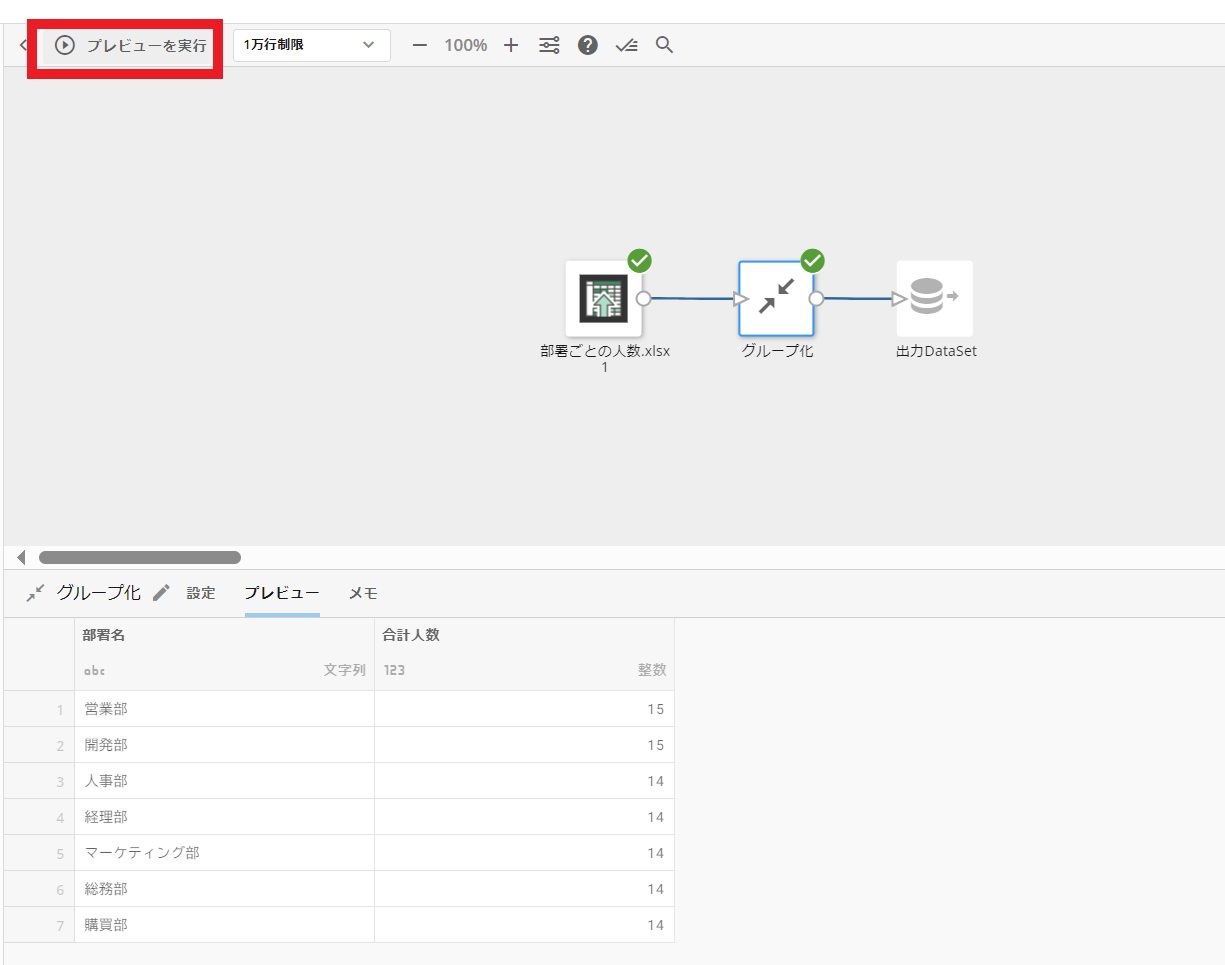
サンプル:Magic ETLでデータをグループ化する
以下では、Magic ETLで社員を部門ごとにグループ化するサンプルをご紹介します。
まず、社員リストファイルをDomoに入力Datasetとしてアップロードします。
次に、「集計」タイルから『グループ化』を選択し、グループ化する項目、集計結果を格納する列の定義、集計方法を選択します。
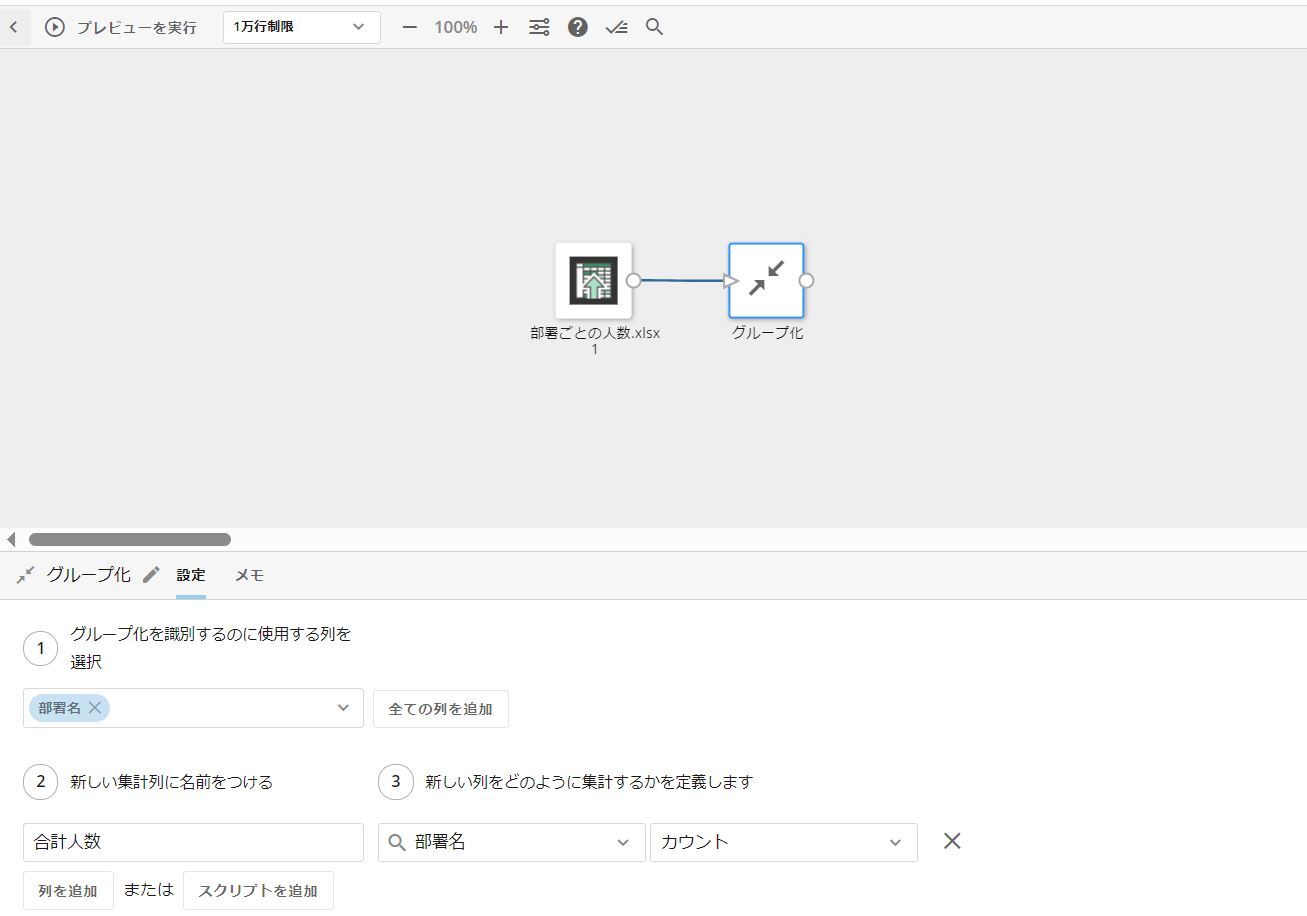
プレビューで確認し、処理が出来ていることを確認したら、出力Datasetを設定して完了です。
-
SQL DataFlow
SQL DataFlowは、Magic ETLを使用する場合と比較し、より技術的な知識を必要とする一方、多くのオプションを利用できるのが最大の違いと言えるでしょう。
SQLの知識があれば、複雑な条件を記述して対応できるため、どうしてもMagic ETLで実現するよりコードを記載した方が良い場合には、こちらの利用をおすすめします。ただし、Magic ETLよりも遅く、予測不可能な場合があるため注意が必要です。
SQL DataFlow利用時の注意点
- パフォーマンスの変動:SQL DataFlowは、特に大規模なデータセットを処理する際に、実行時間が大きく変動することがあります。これは、データベースの負荷やクエリの複雑さ、インデックスの有無などに影響されるためです。
- ロードと書き込み時間の不確実性:SQL DataFlowでは、データのロード(読み込み)や書き込みの時間が予測しにくいことがあります。特に、データベースの状態やネットワークの状況によって、これらの時間が大きく変わることがあります。
- クエリの最適化不足:SQLクエリが最適化されていない場合、特に複雑な結合やサブクエリを含む場合、パフォーマンスが低下し、予測不可能な実行時間を引き起こすことがあります。
- データベースの制約:使用しているデータベースの特性や制約(例: 同時接続数の制限、リソースの競合など)が、SQL DataFlowのパフォーマンスに影響を与えることがあります。
これらの要因が組み合わさることで、SQL DataFlowの実行が予測不可能になることがあります
SQL DataFlowのGUI
SQL DataFlowエディターは、画面上部の「+」ボタンから、「データ」>「SQL」を選択して開きます。
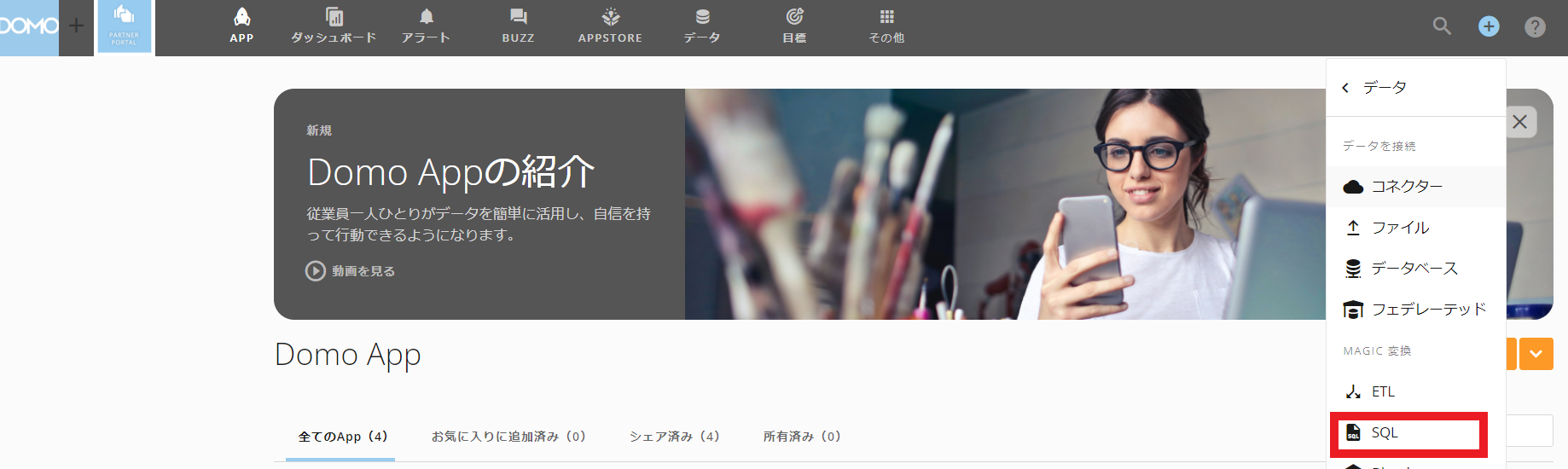
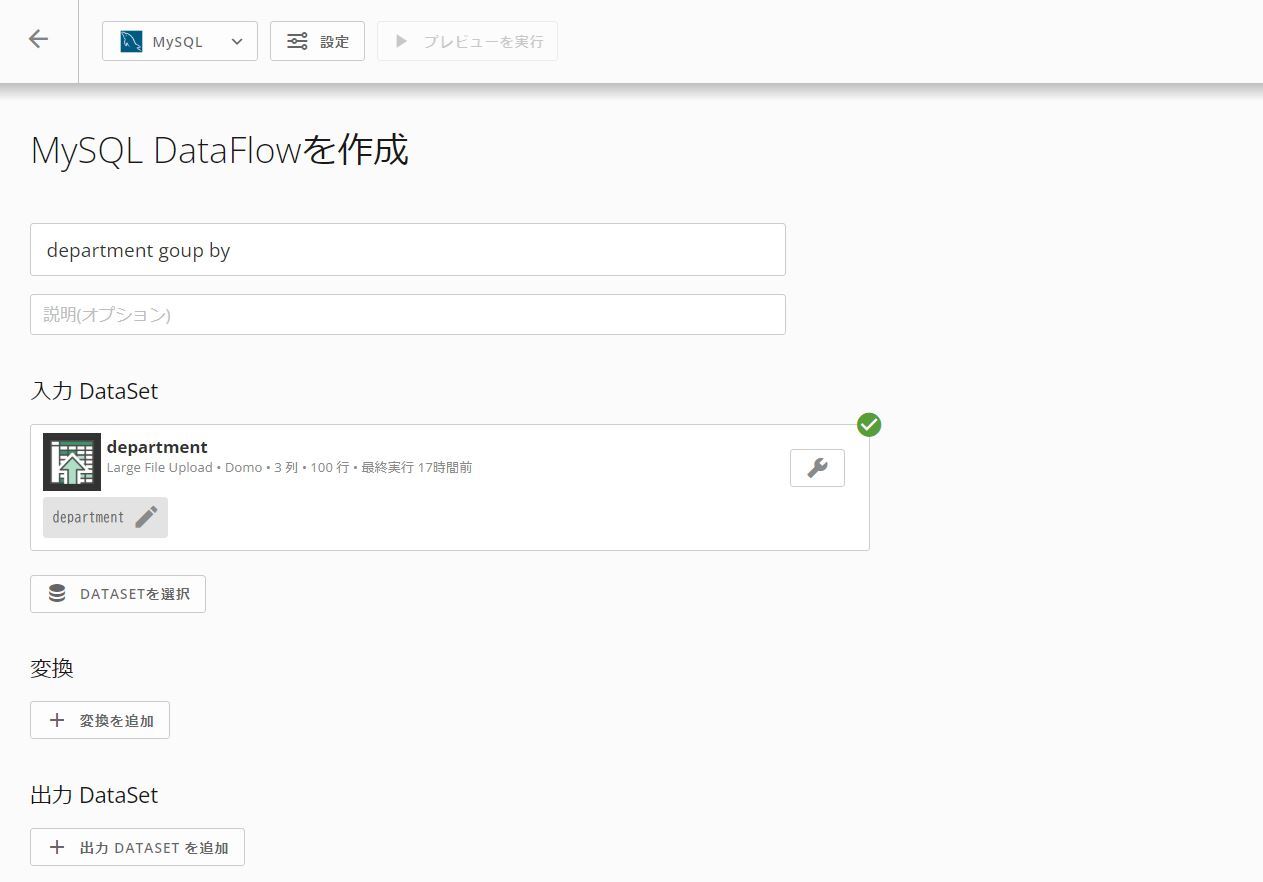
任意の名前を設定し、入力DataSetを選択します。ここの画面から新規にデータをアップロードできないため、まだ入力DataSetが無い場合、まずはDomoへ事前アップロードをしてください。
注意点として、MySQL側の制限によってDataSetの名前とDataSet内の各列の名前は64文字以下であることが定められています。(Magic ETLは制約なし)
「変換」では『テーブル』または『SQL変換』から選択します。
これらの違いは以下の通りです。- テーブル…SELECTステートメントを使用し新しい表が作成される。また、常に出力表が生成され、簡易的なインデックス作成も可能。
- SQL変換…SELECTステートメントを含まないストアドプロシージャを作成するときに利用する。出力表は作成されない。
インデックス作成は、入力DataSetの編集画面から「インデックス作成中」というタブをクリックし、列を選択して作成できます。

サンプル:カスタムSQLを書いてみる
以下では、部門ごとにグループ化するサンプルをご紹介します。サンプルデータは以下を用います。
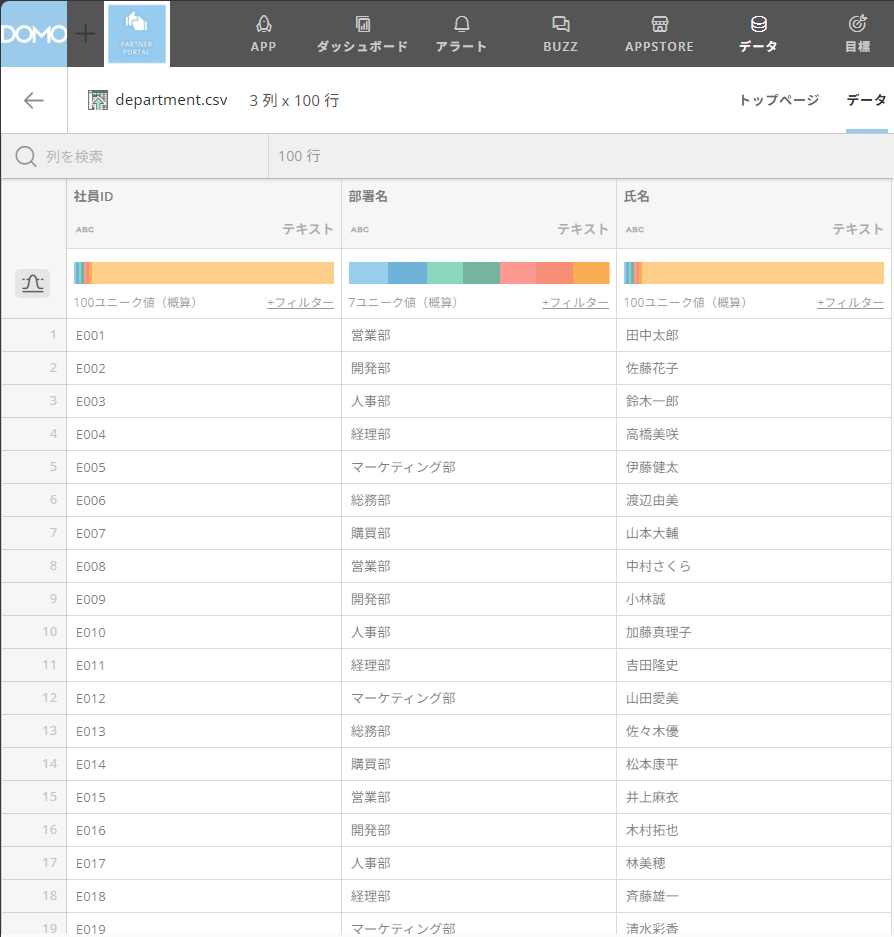
通常のSQLと同様に記載します。今回は部門名でグループ化し、その合計数も一緒に抽出します。式を入力したら、「SQLを実行」ボタンをクリックすると、プレビューが画面下に表示されるので、結果が正常に出力されているかを確認しましょう。
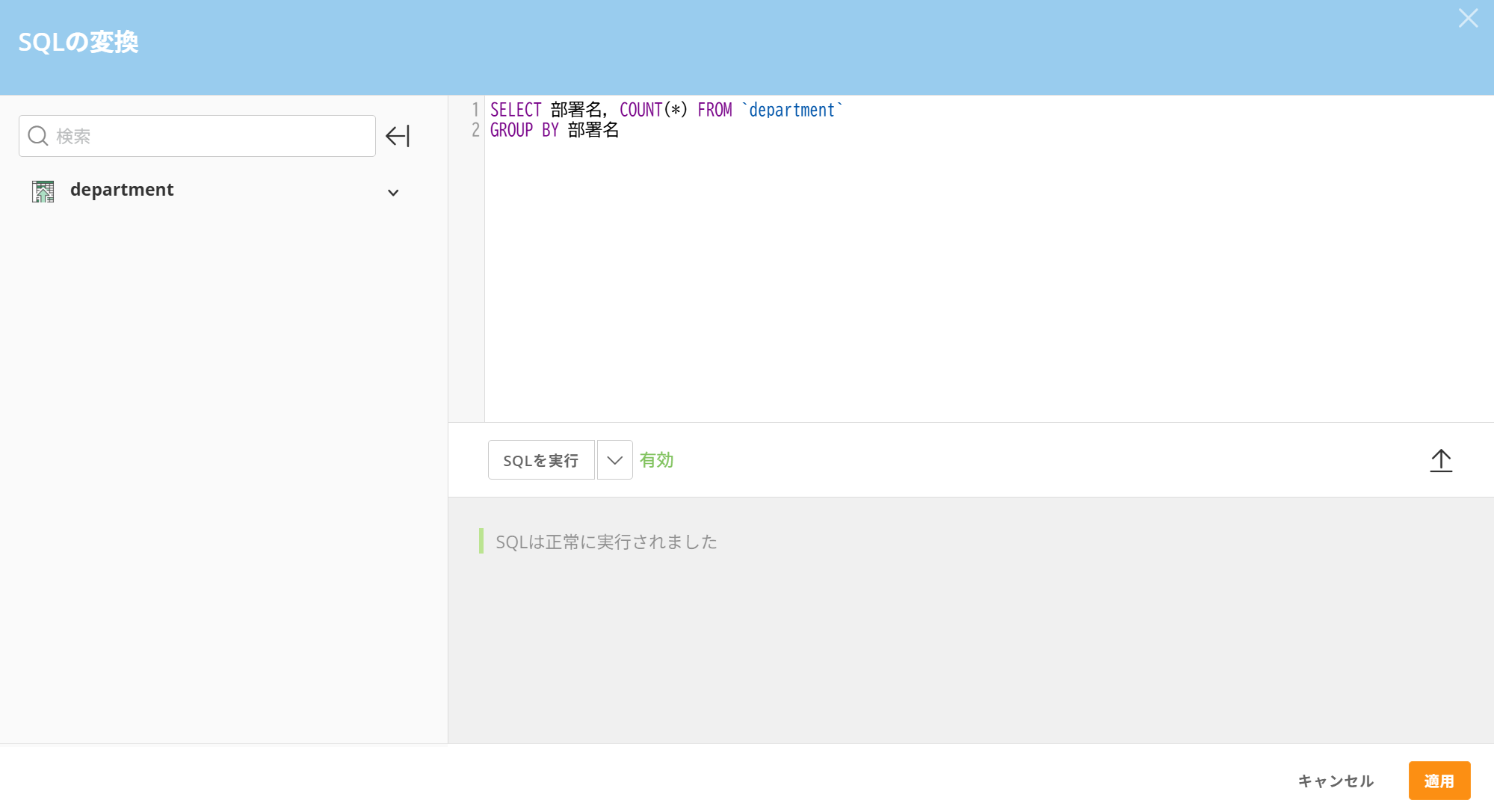
もっと複雑にいくつかのSQLを組み合わせて処理を行いたい場合、変換と出力DataSetどちらにも「ここまで実行」をして試すことが可能です。DataFlowを最後まで連結せず、確認したい範囲を指定しながらテストを行えるため、積極的に活用し効率化していきましょう。
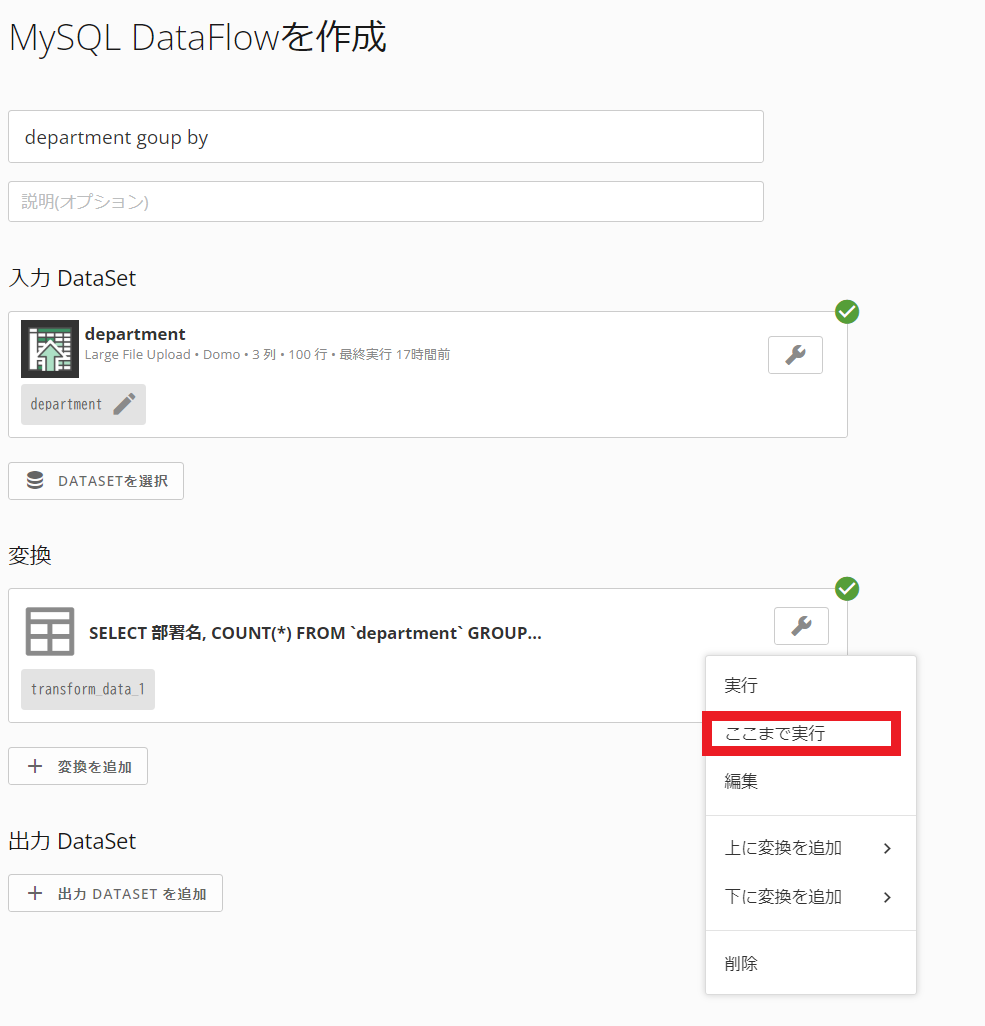
上記は変換処理を1つだけ作成しましたが、変換処理はいくつも組み合わせられます。最終的に「出力DataSet」に出力する結果のSQLを登録すると、出力結果を得られます。
Domoを最短で活用開始!導入後の操作手順を1冊に
ダッシュボード構築やテンプレ活用法が具体的にわかるスタートガイドをDL ▶
Magic ETL DataFlow と SQL DataFlow ならどっちを利用すべき?
前述したとおり、Domoでデータを抽出するならMagic ETLを利用する方が、負荷をかけずに運用できます。特に、ユーザーのマニュアルでの操作が少ないため、ユーザービリティ―の観点から運用コストを下げられるほか、パフォーマンスやクエリの最適化有無による実行時間の違いも、大きな理由として挙げられます。
Magic ETLの優位性
-
パフォーマンスの向上:Magic ETLを使用することで、データフローの実行時間が大幅に短縮されることが多く、効率的な処理が可能になります。
-
パイプラインの堅牢性:Magic ETLは、エラー耐性が高く、日常的なパイプライン(データの収集、処理、変換、そして最終的な出力までの一連のプロセス)の運用においてより効率的で信頼性があります。
-
スケーラビリティ:Magic ETLは、より多くのデータを処理でき、MySQLやRedshiftよりもスケーラブルです。
-
メンテナンスの容易さ:非技術的なユーザーでもパイプラインを維持管理しやすく、技術者がより興味深い作業に集中できるようになります。
-
追加機能:Magic ETLでは、パーティショニングなどの追加のデータストレージ機能が利用可能で、これにより効率性が向上します。
これらの理由から、Magic ETLの移行が推奨されています。
Magic ETLの実際の速度優位性について
実際の速度の違いについては、Domoの公式ブログでは「Magic ETLエンジンは旧バージョンより「約2〜4倍高速」にデータ変換」できると記載があります。
参考:Domo社によるブログ「The new Magic ETL: Faster, smarter, and easier ETL for all」
実際の例として、Domoのコミュニティからも確認することが可能です。
例えば、あるユーザーは、SQL DataFlowで30分かかっていた処理をMagic ETLに作り替えたところ、実行時間が約30秒に短縮されたと報告しています。
参考:Dom社コミュニティフォーラムによる記述「ベストプラクティス:ETL対SQL ETL - Domoコミュニティフォーラム 」
別のユーザーは、データ結合処理をSQLからETL(Magic ETL)に変更したところ、SQLを使用した結が22分であったのに対し、Magic ETLを使用した結合は3分まで短縮できたという報告も上がっています。
参考:Dom社コミュニティフォーラムによる記述 「ETLはSQLよりもはるかに速く参加できる - Domoコミュニティフォーラム 」
これらの違いは主に、SQL DataFlow(MySQLなど)はステップを順次実行するのに対し、Magic ETLは複数の処理を並列に走らせる設計であることが、スピードに違いが出る主な原因として知られています。
ですから、非常に複雑な結合・ループ処理など、Magic ETLで表現しにくいロジックはSQLで対応しますが、パフォーマンス重視かつロジックがMagic ETLで表現可能ならMagic ETLを優先する、という手法がベストプラクティスであると言えるでしょう。
同じ機能で他社はどう成果を出したのか?
kintone連携・Excel連携など、近い活用事例を業種別にまとめた導入事例集をDL ▶
SQL DataFlowからMagic ETLへの移行方法
もしも現在、SQL DataFlowを中心に運用している場合は、Magic ETLへ移行しましょう。以下は、移行にあたって必要なステップとなります。
- データフロー全体の再評価:
まず、SQL DataFlow全体を見直し、不要な入力や使用されていないステップを特定します。これにより、変換する際の効率を高めることができます。 - フィルタリングの最適化:
SQL DataFlow内で最初にフィルタリングされているテーブルがある場合、それをMagic ETLの入力前にフィルタリングすることを検討します。これにより、処理時間を短縮できます。 - 結合の確認:
テーブル間の結合を確認し、結合キーのデータ型が一致していることを確認します。Magic ETLでは、SQLのように自動で型変換されないため、エラーを防ぐために注意が必要です。 - ロジックの計画:
紙に書き出すなどして、Magic ETLでの全体的なロジックの流れを計画します。主要な結合やフィルタリングを含め、どのようにデータを処理するかを考えます。 - Magic ETLの作成:
Magic ETLを開き、必要な入力をすべて追加します。計画に基づいて、結合やフィルタリング、計算を行うタイルを配置します。 - 計算と選択:
必要な計算を行い、最終的な出力データセットを作成します。計算には、FormulaタイルやGroup Byタイルを使用します。 - 出力の検証:
新しいMagic ETLを実行し、SQL DataFlowと並行して結果を比較します。集計や行数を確認し、ロジックが正しく変換されていることを確認します。 - コメントと整理:
Magic ETL内のタイルにコメントを追加し、名前をわかりやすくすることで、他のユーザーが理解しやすいようにします。
これらのステップを通じて、SQL DataFlowをMagic ETLに効率的に変換することができます。
Magic ETLの利用における注意点
基本的にはSQL DataFlowより優れているMagic ETLですが、利用時には以下について注意をする必要があることを覚えておきましょう。特に、特殊な抽出条件やループ処理が必要な時には、SQL DataFlowで解決すべき場合があります。
- 非等価結合の制限:
Magic ETLでは、非等価結合(例: BETWEENを使用する結合)がサポートされていません。これに対する回避策として、データをクロス結合してからフィルタリングする方法がありますが、リソースを多く消費する可能性があります。 - 入力タイルでのフィルタリングの制限:
Magic ETLでは、入力タイルで直接フィルタリングすることができません。ただし、サブセット処理ベータ版(※)を使用して、メタデータに基づくフィルタリングは可能です。 - プレビューでの全行読み込みの制限:
プレビュー時に全行を読み込むことができないため、データフローの途中での検証が難しい場合があります。 - 特定の関数の欠如:
LEASTやグループ連結などの特定のSQL関数がMagic ETLでサポートされていないため、SQLに戻る必要がある場合があります。 - 関数の作成が困難:
Magic ETLでは、SQLのように関数を作成してデータをループ処理することが難しいです。
これらの制限や注意点を考慮しながら、Magic ETLを使用することが推奨されています。
(※)サブセット処理ベータ版は、DomoのMagic ETLで提供されている機能で、データセットの特定の部分を効率的に処理するためのものです。この機能を使用すると、データ全体を処理するのではなく、必要な部分だけを選択して処理することができます。2024年12月時点で、サブセット処理はオープンベータ版としてご利用いただけます。
補足:Domo(ドーモ)Magic ETLと他のデータ変換ツールの比較
これまでの章では主に、Magic ETLとSQL DataFlowの違いを中心に述べましたが、他にもデータ変換ツールとして「Adrenalineデータフロー」、「データセットビュー」などが存在します。これらと比較しても、Magic ETLの方が効率的な運用を行えるため、必要に応じてMagic ETLへの移行を行うと良いでしょう。
-
Magic ETL:
使いやすさと柔軟性が特徴で、ノーコードまたはローコードでデータ変換が可能です。小規模から大規模なデータセットまで対応でき、特にピボットやアンピボットが簡単に行えます。ストリーミング処理により、データの読み込みと出力を並行して行うため、非常に高速です。 -
Adrenalineデータフロー:
大規模データセット(300万行以上)に最適で、データの集約や要約に特化しています。SQLを使用して変換を行い、非常に高速に処理できますが、行ごとの変換には向いていません。 -
データセットビュー:
軽量な変換を行うのに適しており、Excelのようなインターフェースで直感的に操作できます。リアルタイムのデータ探索に優れており、データが保存されないため、クエリの再実行が必要です。 -
SQL DataFlow:
非等価結合やストアドプロシージャの作成に適しており、SQLの知識が必要です。Magic ETLよりも遅く、予測不可能な場合がありますが、特定のSQL機能が必要な場合に有用です。
Domo導入前に確認すべき13の重要ポイント
要件定義・社内準備・運用体制などをチェックできる実践的な確認リストをDL ▶
まとめ
いかがでしたでしょうか。本記事では、DomoでSQLを利用して、複雑な条件によるデータ抽出方法と、それらの違いについて解説しました。
データ抽出方法は主に、『Magic ETL』というGUIベースで処理が組める機能、または既存のSQLコードの記述によってデータを抽出する『SQL DataFlow』が存在します。
しかしながら、SQL DataFlowでは使い勝手の観点と、実行時間の不確実性の観点から、利用コストが高い一方で効率性はMagic ETLに劣ってしまう側面もあります。ですから長期的な観点で言えば、出来る限り運用はMagic ETLで行うことが望ましいでしょう。
NDIソリューションズでは、BIプラットフォーム Domoを利用した企業事例集の公開、セミナーの開催を行っております。
Domoまとめて導入事例集
Domoセミナー / イベント情報
また、実際にDomoを動かしていただけるBI無料トライアルもご用意いたしました。ご興味がある方はぜひ上部メニューよりお申し込みください。
当サイトでは、BIツールに興味のある方へ、参考になるダウンロード資料をご用意しております。「BIツール初心者向けまるわかりガイド」と「統合型BIプラットフォーム Domo基本ガイドブック」は、データ活用やBIツール導入のポイントが把握できる資料になっています。BIツールご検討の参考に、ぜひダウンロード資料をご覧ください。
公開日:2026年3月5日

藤木 卓馬 |
ブログ監修者 NDIソリューションズにて約10年ソリューション営業を担当。Domoやkintoneをはじめ数多くのクラウド製品販売の経験を活かし、複数ソリューションを組み合わせたお客様課題の解決を提案している。現在はDomoソリューションコンサルタントのチームリーダーとして、お客様のデジタル化、データ活用を中心としたDX推進をサポート。 |
