
RAG + 生成AIで正確な回答が得られるの?仕組みを詳しく解説

生成AIの一部であるLLM(大規模言語モデル)は、インプットされた情報に基づいて回答をテキストベースで返す能力に優れています。生成されたテキストは、まるで人間が書いたように読みやすく、ユーザーが入力したプロンプトに対して幅広い詳細情報を提供してくれるため、ビジネス活用を検討する企業は後を絶ちません。
一方で、LLMが応答を生成するにはこれまでに学習し蓄積された情報を利用するため、数週間から数年前まで遡った古いデータが使用されることもあり、また答えが見当たらない場合は虚偽の回答をしてしまう場合がある、といったデメリットもあります。
こうした背景により、組織や企業の独自情報などを回答してくれるチャットボットを求めている場合、ChatGPTなどの生成AIチャットボット利用を断念せざるを得ませんが、そうした課題もRAG(検索拡張生成)を使えば解決できるのです。
本記事ではRAGの仕組みや利用におけるメリット、実際の活用事例について解説します。RAGの特徴やメリットを理解し、ぜひ生成AIをビジネス活用に役立てみましょう。
- RAG(検索拡張生成)とは?生成AIのビジネス活用で重宝される理由
- RAGで生成AIを強化する仕組み
- RAGと生成AIの最新活用事例
- RAGと生成AI「ChatGPT」を組み合わせて業務で使う
- RAGとファインチューニングの違い。コスパの良いのはどっち?
- RAGは100%の回答精度を実現するものではない
- まとめ
RAG(検索拡張生成)とは?生成AIのビジネス活用で重宝される理由
RAGとは、外部ソースからデータを取得し、生成AIモデルの精度と信頼性を高める手法です。語源はRetrieval-Augmented Generationの頭文字を取ったものであり、日本語訳では「検索拡張生成」とも呼ばれています。以下では生成AIとRAGの関係性、RAGを利用するメリットについて見ていきましょう。
生成AIのビジネス活用における限界
ユーザーが欲しい回答を得るには、実は生成AIの利用だけでは限界があります。LLM(大規模言語モデル)は学習したデータの中から、ユーザーが入力したプロンプトに関連する情報を探して回答します。その際に、広く公開されている一般的な情報を基に回答をするため、クローズドな情報には対応できません。例えば、「自社の今年の営業部の売上高を知りたい」などといった質問には、LLMで回答を期待することができないのです。
さらに、公開された情報を使用する場合にも、時には数年前の古いデータなどを利用することがあるほか、学習データ不足やデータの誤った組み合わせなどにより、誤った回答を生成する(ハルシネーション(※))ことがあります。
ですから、特にビジネス利用において最新情報や決まったデータ範囲から正確な回答をして欲しい場合に、生成AIの利用だけではかなりリスクが高い状況を生み出してしまうため、どのような利用をしたいのか事前に目的を決めることが大切なのです。
生成AIの代表的なモデルであるChatGPTの基本的な機能や特性については、こちらの記事で詳しく解説していますので、ご覧ください。
「ChatGPTって何がすごいの?できること・できないこと」
(※)生成AIのハルシネーションとは、AIモデルが実際には存在しない情報や事実を生成してしまう現象を指します。これは、AIがトレーニングデータに基づいて新しい情報を生成する際に、誤った結論や不正確な情報を出力することがあるためです。
RAGはユーザーと信頼を築くツール
RAGを利用すると、研究論文の脚注など、信頼できるソースを使って回答が生成されるため、ユーザーからの信頼感も得られるようになります。
さらに、生成AIを利用する際にこれまで懸念されていた「ハルシネーション」も、RAGの技術を導入すればクエリに関連した確実な情報を得られるようになるため、こうした懸念も大幅に軽減できます。
RAGで生成AIを強化する仕組み
RAG(Retrieval-Augmented Generation)は、情報検索と生成AIを組み合わせたアプローチで、より正確で文脈に沿った回答を生成するための手法です。以下にその仕組みを説明します。
RAGアーキテクチャ
RAGのアーキテクチャは、LLM(大規模言語モデル)の能力を強化するために、強力な情報検索メカニズムを組み合わせ構成されており、主に「情報検索(Retriever)コンポーネント」と「生成(Generator)コンポーネント」から成り立っています。
それぞれのコンポーネントの役割について見ていきましょう。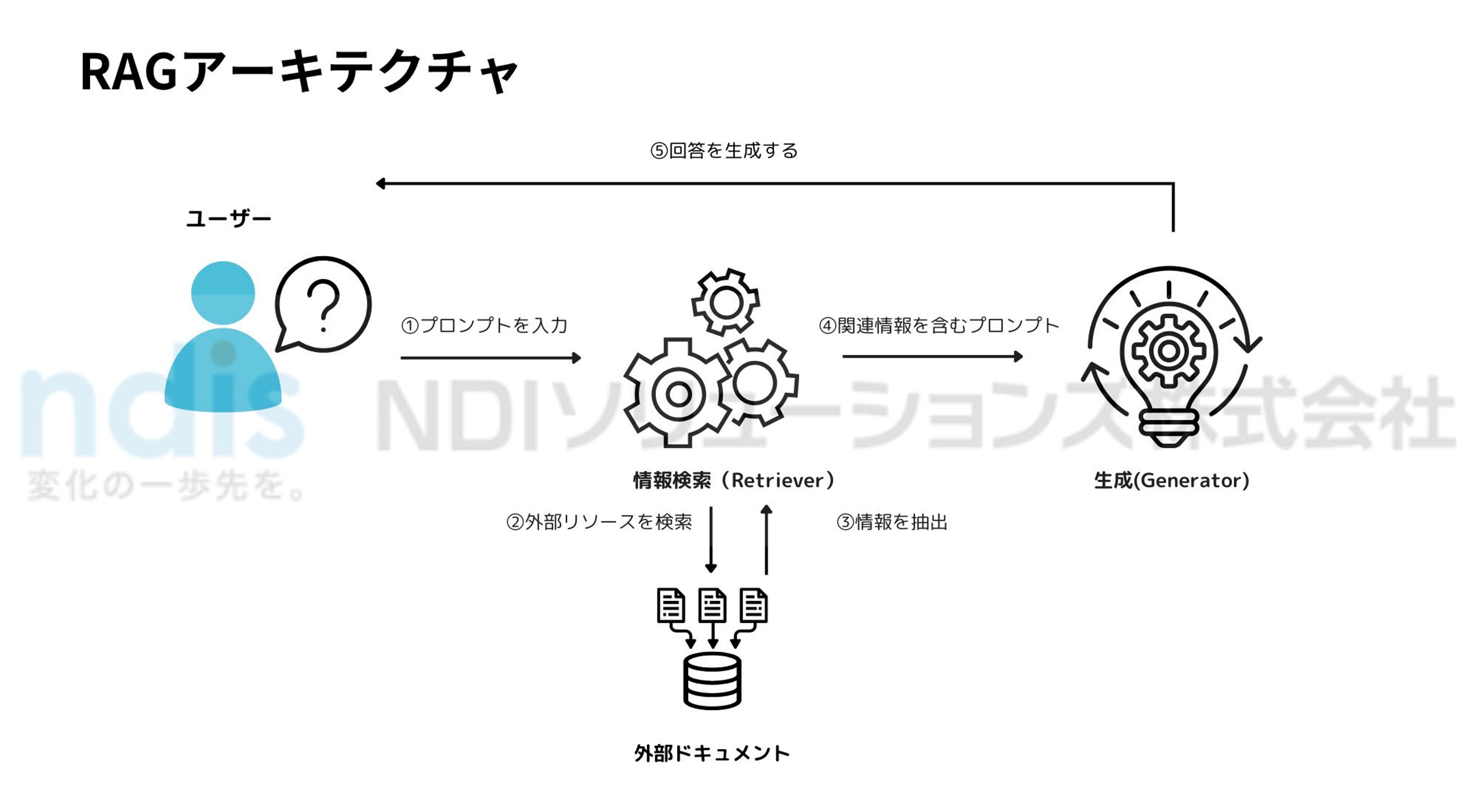
情報検索(Retriever)コンポーネント
【機能】
情報検索(Retriever)の役割は、クエリに対する回答を生成するのに役立つ関連する文書や情報を見つけることです。入力されたクエリを受け取り、データベースを検索して有用な情報を取得します。
【情報検索方法の種類】
情報検索方法には2種類あります。
- Dense Retrievers(密な情報検索):
ニューラルネットワークベースの手法を使用して、テキストの密なベクトル埋め込みを作成します。テキストの意味が重要で、正確な言葉よりも意味的な類似性を捉える必要がある場合に優れた性能を発揮します。 - Sparse Retrievers(疎な情報検索):
文書中に含まれる単語の重要度を評価するTF-IDFや、検索クエリに最も一致する文章を探しだす統計アルゴリズムBM25(Best Matching 25)のような用語マッチング技術に依存します。クエリにユニークまたは珍しい用語が含まれている場合、正確なキーワードマッチを見つけるのに特に有用です。
生成(Generator)コンポーネント
【機能】
生成プログラムであるジェネレーターは、最終的なテキスト出力を生成する言語モデルです。入力クエリと情報検索(Retriever)コンポーネントによって取得されたコンテキストを使用して、一貫性があり関連性のある応答を生成します。
【情報検索(Retriever)との相互作用】
生成コンポーネントは単独で動作するのではなく、情報検索コンポーネントが提供するコンテキストを利用して応答を生成します。この応答方法によって出力が単にもっともらしいだけでなく、詳細と正確さに富んだものとなるのです。
上記のようにRAGのアーキテクチャは、情報検索コンポーネントと生成コンポーネントを組み合わせることで、より豊かで正確な情報提供を可能にしています。
RAGについて導入を検討する際に、よくセマンティック検索とどう異なるのか気にする方もいるようですので、以下ではそれらの違いについて解説します。
セマンティック検索(意味検索)との違い
セマンティック検索はRAGを支える要素でもあり、外部ナレッジソースを回答に追加したい組織のRAGによる回答結果を強化する役割を果たしています。
セマンティック検索とは「セマンティクス = 単語の意味に関する研究」を利用した手法で、ユーザーのクエリの意味を理解し、時には文章構造をも理解しながら、それに基づいて関連性の高い情報を検索する技術です。従来のキーワードベースの検索とは異なり、文脈や意味を考慮して検索を行います。例えば「東京と博多の最短距離」について質問した場合、直線距離ではなく陸路の回答を示してくれるのも、この技術のおかげです。
このように、セマンティック検索はユーザーのクエリと関連性の高い情報を効率的に検索することに焦点を当てているため、従来のRAGでは知識集約型であるため回答が限られる一方、セマンティック検索によってRAGの技術が補完されているのです。
それでは、RAGとはそもそも何が発端だったのでしょうか。以下では歴史を振り返ってみます。
RAGの歴史
RAG(Retrieval-Augmented Generation)は比較的新しい技術で、生成モデルと情報検索技術を統合したアプローチです。その間接的なルーツを辿ると、1970年代初頭まで遡ります。当時研究者たちによって、自然言語処理技術を用いて質問化応答システムのプロトタイプが開発されていました。
最初は野球のテーマなど、限られた範囲での質問回答アプリから着手されていたのですが、それが徐々に機械学習エンジンの成長へとつながりました。1996年にはAsk Jeeves(現在のAsk.com)が設立され、自然言語検索を取り入れた質問応答システムとして知られるようになりました。このサービスは1990年代後半から2000年代初頭にかけて人気を博し、質問応答技術が一般社会に広まる一助となりました。ただし、RAGの具体的な実現には、それ以降の機械学習や大規模言語モデルの発展が不可欠でした。

【参考】What Is Retrieval-Augmented Generation aka RAG | NVIDIA Blogs
次に、今日における社会やビジネスにおけるRAGの活用事例について見ていきましょう。
ChatGPTを使えば十分、と思っていませんか?
選び方を間違えると効果が出にくいケースも
「生成AIと機械学習AI AIチャットボットの違いがわかるガイド」で学ぶ
RAGと生成AIの最新活用事例
昨今、多くの業界で人材不足が深刻化しています。いかに効率化するかを意識した場合、必然的にAIに頼らざるを得ない時代に突入してきているものの、従来のAIでは回答品質を担保できるだけの技術レベルに達していないことが課題となり、ジレンマを抱える人が少なくありません。
しかしRAGの技術を活かすことで、これらの相反する課題を簡単に乗り越えられるようになります。
この章では3つの先進的な事例をご紹介しましょう。
Eコマースにおけるカスタマーサポートの強化
昨今のEコマースにおいて、顧客満足度とロイヤリティを強化するには素早いレスポンスが、かつてないほどまでに重要視されてきています。こうした課題にはAIチャットボットの導入がまず検討される一方、複雑な質問やトレーニングデータの範囲外にある独自シナリオが必要な際には対応ができず、壁にぶつかりやすいのが課題です。
これを解決するため、ある大手Eコマースプラットフォームは、カスタマーサポートのチャットボットにRAGを実装しました。RAGモデルは、顧客とのやり取り、製品情報、よくある質問(FAQ)の膨大なデータベースでトレーニングされており、特定の製品の詳細、過去のお客様とのやり取り、関連するFAQなどの関連情報をデータベースから取得して、顧客へカスタマイズした回答生成を行っており、業務効率化を実現しています。
製造業におけるサプライチェーンマネジメントの最適化
製造業におけるサプライチェーンマネジメントには、原材料の調達から製品の配送まで、複数のプロセス調整が含まれます。サプライチェーンの最適化に使用される従来のAIモデルは、需要の急激な変化、供給の混乱、または新しい市場動向に適応するのは難しく、適切な結果を出しづらい点が課題として知られています。
ある製造会社では、サプライチェーンを最適化するためにRAGの導入に踏み切りました。RAGモデルを活用することで、サプライチェーンデータ、市場動向、生産スケジュールを含むデータベースが統合され、サプライチェーンの混乱や需要の変化に直面した場合、モデルは代替サプライヤー、生産能力、過去の需要パターンなどの関連情報を考慮した戦略を提案してくれます。
これはビジネスのこれまでの流れ、独自のデータが無いと実現できないことであり、こうしたビジネス戦略策定にもRAGは大いに力を発揮してくれるのです。
医療業界における診断と治療判断の改善
医療業界の深刻な人手不足についても、RAGが効果を発揮します。特に、正確な診断と患者への個別治療案を迅速に提供することが求められる一方、これらを解決しようとするとAIに頼らざるを得ません。しかしながら、従来の医療AIでは事前に学習されたデータセットに回答が依存してしまうため、新たな医学研究結果を利用した回答が出来ないほか、独特なケースに対しても適切な診断結果を下すにはまだ技術が及びません。
こうした課題に対し、ある医療機関ではAIを活用した診断ツールにRAGを導入することで解決の道を見出しています。医学文献、患者記録、臨床ガイドラインなどのデータモデルを統合し、そこからAIモデルが個々のケースに関連する医学研究や類似診療事例や治療結果を取得します。こうしたことからより患者にパーソナライズされた診断を下せるようになり、医療業界のデジタル化の進化にも貢献するようになってきています。
上記のように、社会へ生成AIが浸透していくのと共に、RAGの活用も進化を遂げています。
ただし「RAGは100%の回答精度を実現するものではない」でも後述しますが、これらの回答を完全に鵜呑みにしてしまうのは危険です。参考にしつつ、参照データが更新されていない、もしくはデータに無いことをユーザーが聞いている可能性もあることもユーザー側の認識として押さえておくべきでしょう。これらを防ぐために、例えばユーザーが入力できるプロンプトを画面上から限定するなど、使い方についての対策も同時に考慮が必要です。
【参考】RAG in Action: Real-World Case Studies of Improved AI Performance | by Raghav | Aug, 2024 | Medium
次の章では導入が実現しやすい、ChatGPTとRAGを組み合わせる方法についてご紹介しましょう。
RAGと生成AI「ChatGPT」を組み合わせて業務で使う
自社で生成AIの活用を始めようと、既にChatGPTを業務で利用している企業も日々増加傾向にあります。しかしながら、ハルシネーションや社内に関する独自回答をしてもらえない点で、ChatGPTの利用が限定的になってしまっているケースも少なくありません。
しかし、RAGでデータ抽出した結果をChatGPTと連携することで、そうした課題を解決できます。
ChatGPTの仕組みや業務利用方法については、こちらの記事で詳しく解説していますので、ご覧ください。
「【2024年版】ChatGPTと生成AIの全体像や違いを図解で丁寧に解説」
RAGとChatGPTの連携手順として、まずあらかじめ用意しておいた企業独自の情報が詰まったドキュメント(社内規定、製品マニュアル等)を格納します。そこからユーザーのプロンプトに応じて最も関連する情報を検索して抽出した後に、ChatGPTへデータを連携します。ChatGPTは文章生成を得意とするため、連携することにより適切な回答文を得られます。
なお、これらの開発が全て行われた製品が、AIチャットボットシリーズCB3からリリースされている、RAG with GPTオプションです。
【CB3 RAG with GPTアーキテクチャの概要】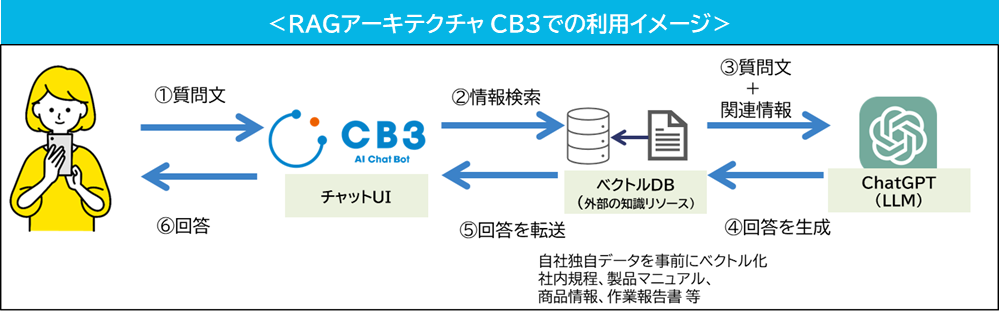 【質問と回答イメージ】
【質問と回答イメージ】

もちろん自社開発をすることもできますが、RAGの導入において非常に手間がかかるポイントもあり、実際に使えるまでには時間がかかります。そのため、スピード感をもってすぐに導入をしたい企業は、こうした製品導入で素早く業務で活用しています。その手間と製品導入がオススメである理由について、以下で説明します。
効率化を重視するならRAGサービスを導入するのがおすすめ
チャットボット導入で一番手間がかかるポイントは、なんといっても事前学習データの準備です。
RAGを利用せずに質問回答集(FAQ)で回答するチャットボットを整備する場合、例えば社内の人事総務分野で事前にデータを用意するとなると、以下のような範囲を網羅した学習データを用意する必要があります。
| カテゴリ | データ内容 |
|---|---|
| 給与 | 昇給 賞与 年末調整 |
| 社会保険 | 住所変更 結婚・出産 給付金申請 |
| 就業 | 勤怠管理 シフト勤務 時間外勤務 |
| 教育・研修 | 資格取得昇給 所与 年末調整 |
| 組織 | 組織改正 組織図 |
| 福利厚生 | 社宅・社員寮 社内イベント 財形貯蓄 |
| 契約書 | 契約書押印 契約書保管 |
| リスクマネジメント | 災害対策 自己・不祥事 セキュリティ |
人事総務関連の問合せに対応する社内チャットボットとして機能させるには400種類(弊社の提供事例より算出)程度の回答集を用意し、さらにシステムへ登録する手間がかかります。しかしながら、こうした学習テンプレートが既に用意された製品や回答に対する質問を生成できる機能を持つ製品の導入ができればその工数は削減できます。もちろんWord、Excel、PDFといったファイルから簡単にデータをアップロードするだけで使えるRAG機能が搭載されている製品を導入すれば、さらに工数は大幅に削減されます。
また、よくある質問の精査も慣れていないとかなり難しいため、既にナレッジがある企業に依頼した方が効率的です。
質問回答集(FAQ)で回答するチャットボットは事前学習データの準備が大変ではありますが、誤った情報の提供を最小限に抑え、高い信頼性と正確性を求めるビジネスユースに最適、というのが長所です。
事前のトレーニングをするという点では、ファインチューニングという選択肢もありますが、コストパフォーマンスの面でいくらか違いがあります。
次の章ではRAGとの違いとコスパの違いについて解説していきます。
ChatGPTと従来型AIチャットボット、
何がどう違うのか説明できますか?
「生成AIと機械学習AI AIチャットボットの違いがわかるガイド」で確認する
RAGとファインチューニングの違い。コスパの良いのはどっち?
ファインチューニングは、特定のタスクにモデルを適応させるための手法です。場合によっては、RAG(検索拡張生成)よりコストパフォーマンスに優れた選択肢となることがあります。以下では、ファインチューニングの概要と、RAGとの違いについて見ていきましょう。
ファインチューニングとは
ファインチューニングとは、既存の機械学習モデルを特定のタスクやデータセットに適応させるためのプロセスを指します。一般的に、事前に大規模なデータセットでトレーニングされたモデルを基に、より小規模で特定のデータセットを用いて再トレーニングを行うため、モデルは特定のタスクに対して高い精度を発揮することが期待されます。
ファインチューニングの利点は、既存の知識を活用しつつ、特定のニーズに応じたカスタマイズが可能である点です。しかし、ファインチューニングには以下のような手間がかかるので、導入において労力が必要なことが知られています。
- 多くの計算資源と時間が必要であり、特に大規模なモデルの場合に多大なコストがかかる
- 新たな汎用モデルが登場した場合、再学習コストがかかる
- 新たな独自データセットの準備やハイパーパラメータ(※)の調整も重要であり、これらが不十分であると、期待した成果を得ることができない
(※)ハイパーパラメータとは、機械学習アルゴリズムの振る舞いを調整するための設定。学習率や反復学習の回数など、学習前に設定する。
なぜRAGの方がコスパが良いのか
RAGの主な利点は、事前にトレーニングされた生成モデルに対して、外部の情報源から関連情報を動的に取得し、それを基に応答を生成する点にあります。これにより、ファインチューニングのようにモデル全体を再トレーニングする必要がなく、計算資源や時間を大幅に節約できます。
さらに、以下のような理由からもRAGが優れていると注目されています。
- RAGは新しい情報やデータに対しても柔軟に対応できるため、常に最新の情報を提供できる
- 回答に独自情報を必要とする場合にも、外部データベースを活用することで、迅速かつ正確な情報提供を実現する
必ずしもすべてのケースに該当するのではないので注意
RAGがコストパフォーマンスに優れているとはいえ、すべてのケースにおいて最適な選択肢であるとは限りません。特に、非常に専門的なタスクや、特定のデータセットに対して高い精度が求められる場合には、ファインチューニングが依然として有効な手法となることがあります。
例として、RAGは外部情報に依存するため、情報源の信頼性や更新頻度が結果に大きく影響します。したがって、情報源の選定や管理が重要です。またRAGの導入には、情報検索システムの構築や維持が必要であるほか、RAGは生成モデルの性能に依存するため、基礎となるモデルの選択も同じく重要です。
これらの要因を総合的に評価し、特定のタスクや環境に最適な手法を選択することが求められます。
以下では、RAGが苦手とすること、使いこなす方法について解説します。
RAGは100%の回答精度を実現するものではない
これまで見てきたように、RAGは生成AIの回答結果を補完し、独自情報までカバーできる強力な手法ですが、すべての状況で完璧な精度を保証するものではありません。使い方によってはRAGの効果を上手く利用できないことも考えられます。この章ではRAGに期待すべきでないこと、またどのように効果的に利用すべきなのかについて説明します。
RAGに期待すべきでないこと
RAGは情報検索と生成モデルを組み合わせた手法であり、多くのタスクにおいて有用ですが、いくつかの限界があります。
参照データに存在しない回答は返せない
まず、RAGは外部情報源に依存するため、情報源の信頼性や正確性が結果に直接影響します。
そもそも参照させるデータに無い回答を期待しても、当然ながら望む回答は得られません。
100%正確な回答は難しい
誤った情報や古いデータを基にした応答は、ユーザーに誤解を与える可能性があります。また、RAGは特定の文脈やニュアンスを完全に理解することが難しい場合があるため、特に曖昧な質問や複雑な文脈を含むタスクでは、生成される応答が期待に沿わないこともあり得ます。
さらに、RAGは事前にトレーニングされた生成モデルに依存しているため、モデル自体の限界も考慮する必要があります。例えば、モデルが特定のドメイン知識を持っていない場合、その分野に関する質問に対して適切な応答は返せません。
高速なレスポンス
RAGは外部リソースを検索し回答を作成するため、どうしても検索時間を必要とします。そのため、業務利用で問題ないレベルの速度であっても、ユーザーのプロンプトと同時の回答生成を期待してしまうと、少し遅く感じることがある可能性があります。
100%の精度を期待するのは難しい一方で、設定次第で精度を向上できることが知られています。次の章では、その方法について解説します。
RAGの精度をもっと高めるには?
RAGの精度を高めるためには、大きく分けると以下2つの点を如何に達成させるかがポイントとなります。
- ユーザーのプロンプトに最も関連するドキュメント群を抽出する
- 抽出したドキュメント群を最大限活用し、正しい回答を得る
これらを改善するには、それぞれドキュメント群の検索効率に向けた調整と、LLMへのデータの渡し方を効率化する手法などを用います。
また定期的なメンテナンスとして、以下は必ず行いましょう。
- 情報源の選定と管理を徹底する
- 信頼性の高い情報源を使用し、定期的にデータを更新する
- 生成モデルのトレーニングデータを増やし、特定のドメインに特化したデータセットを使用する
- ユーザーからの回答に対するフィードバックを収集する
まとめ
この記事では、生成AIのビジネス活用においてRAG(検索拡張生成)の技術が必要とされている背景や、RAGの仕組み、導入事例や注意すべきポイントを解説しました。
生成AIは、ユーザーのプロンプトに対して回答できる範囲に限界があります。特に業務で利用する場合、企業独自のデータを用いた回答が必要な場合に、生成AIだけでは対応ができません。RAGは外部データを参照し、プロンプトに最も関連した回答を抽出してくれるため、生成AIとRAGを組み合わせれば、創造的な回答の他にも正しい回答結果が必要な場面にも対応できる、といった効果を発揮します。
生成AIのデメリットをRAGの技術でカバーすることにより、ビジネスの幅は飛躍的に増えるでしょう。
当サイトでは、AIチャットボット、生成AI、ChatGPT、動画活用に関するダウンロード資料をご用意しております。ご興味のある方はダウンロードいただき、資料をご活用ください。
【資料】生成AIと機械学習AI AIチャットボットの違いがわかるガイド【〇×比較表】
【資料】生成AI 基本の『き』
RAGも使えるAIチャットボットトライアル
また、NDIソリューションズが提供する「動画活用×生成AIツール Video Questor(ビデオクエスター)」は、組織全体でのナレッジシェアリングを促進するツールです。Video Questorは、動画の内容を自然言語で要約したり、特定のトピックに関する質問に回答したり、動画の該当部分をピックアップして提示することができます。これにより組織内で共有される研修や会議などの長い動画の中から必要な情報へ迅速にアクセスでき、時間を節約できます。
Video QuestorとQuestellaの詳細については、Video Questor製品サイトをご覧ください。

公開日:2024年12月24日
SHARE

おすすめ記事



